
- TOP
- 空海
紙やPDFを高速かつ高精度にデジタル化し、
AIが理解・整理まで自動で行います。
空海が選ばれる3つの理由
- かんたん – ドラッグ&ドロップするだけで取込み完了
- すばやい – 最短30秒でAIが理解しJSON化
- つよい – テンプレート方式で新しい帳票にも即対応
機能ハイライト
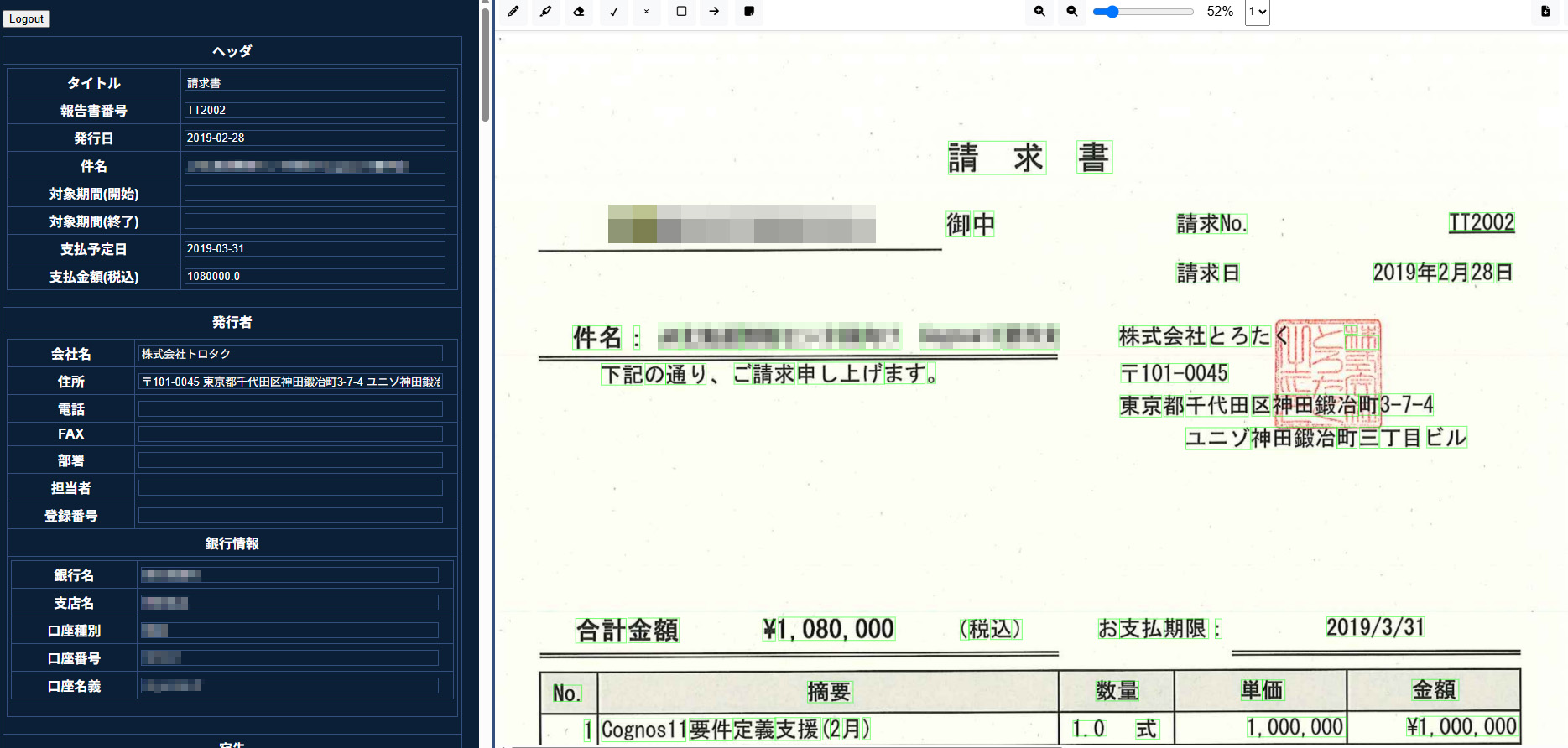
- 高精度OCR – かすれた文字も、手書き文字も、逃さない。
- AI理解&整理 – 読む、考える、まとめる――全部AIにおまかせ。
- REST API – あなたの基幹システムと、即シンクロ。
- 同期・非同期処理 – 1枚でも1万枚でも、スピードは同じ。
- カスタムJSON – 欲しい項目だけ、思いのまま。
システム概要
本プロジェクトは、請求書などのPDFから⽂字情報を抽出し、整理されたJSONデータとして出⼒する仕組みです。Google Cloud VisionによるOCRとOpenAIのChat APIを組み合わせることで、書類の内容を⾃動的に構造化します。Webブラウザ上では編集可能なレポート画⾯も提供しています。
使⽤技術
- Python 3 / FastAPI – サーバーアプリケーション[^1]
- Google Cloud Vision API – PDF画像から⽂字を取得[^2]
- OpenAI API – 取得した⽂字を解析して請求書データを⽣成[^2]
- pdf2image / OpenCV / PyMuPDF – PDFを画像へ変換し、OCR⽤に加⼯[^2]
- Jinja2 – HTMLテンプレートとしてレポートを⽣成[^3]
- JavaScript – 画像上のハイライトや拡⼤縮⼩などブラウザ側の操作[^4]
システム構成図


データフロー
- 1.PDFアップロード
- /uploadエンドポイントで受け付けます。PDFはstorage/{timestamp}ディレクトリに保存されます[^5]。
- 2.OCR処理
- process_fileがPDFを画像化(300dpi)し、Vision APIで⽂字と位置情報を取得します[^6][^7]。
- .AI解析
- OCR結果をプロンプトと共にOpenAIに送り、請求書JSONを⽣成します[^8][^9]。
- OCRの結果には座標情報を持つJSON形式と、単なるプレーンテキスト形式の2種類があります。
- スキーマへのマッピング処理はOpenAIに委ねています。
- プレーンテキスト形式の場合、後続プログラムで決め打ち処理を⾏えます。
- 4.結果保存
- ⽣成されたJSONとOCR結果、ページ画像を同じディレクトリに保存します[^10]。
- 5.レポート表⽰
- /report/{id}でHTMLレポートを表⽰。編集フォームとOCR画像を並べて表⽰します[^11] [^12]。
- 6. API利⽤
- /v1/invoices:analyzeではPDFを送信するとJSONが即時返ります[^13]。
⾮同期版/v1/invoices:analyzeAsyncも⽤意されています[^14].
- /v1/invoices:analyzeではPDFを送信するとJSONが即時返ります[^13]。

よくある質問
- Q. セキュリティは大丈夫?
- A. 通信はすべてTLS1.3で暗号化。データは日本リージョン内で保管できます。
- Q. 手書きの伝票も読める?
- A. Google Cloud Visionのハイエンドモデルを利用し、手書きでも高精度です。
- Q. ワークフローに合わせて項目を変えたい。
- A. 管理画面でJSONスキーマをGUI編集、すぐ反映できます。

